In this article
More details on the Azure Storage replication
Iteration 1
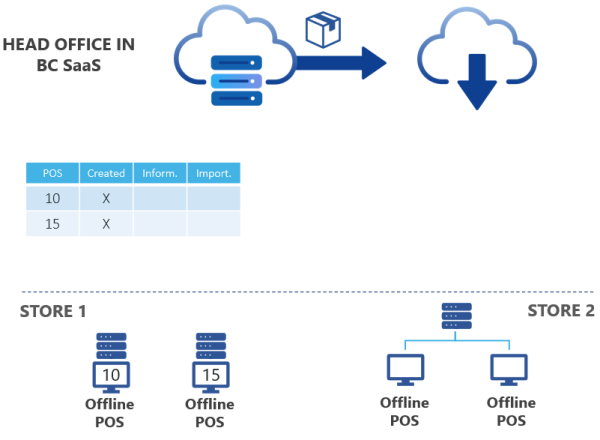
As a first step, you must create your own Azure Storage Account.
You set up and run the Scheduler Jobs in HO in SaaS. When you run the job, the package is created in Azure Storage, and a record with information on where the package should go.
Iteration 2
In the example below, POS15 calls HO to see if there is any data for it. If there is, HO in SaaS logs that POS 15 has been informed about the package.
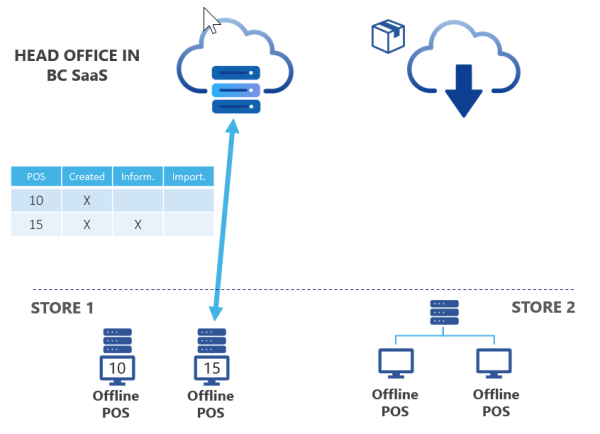
Iteration 3
The POS then goes to Azure Storage, fetches the package down to the POS, which reads in the data, and once the data has been imported the POS communicates to HO in SaaS that it has successfully imported the data:
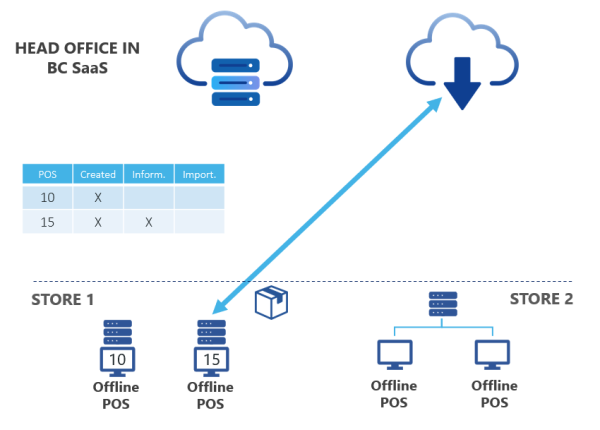
Iteration 4
The logs in the central database or HO in SaaS are updated accordingly. There is good overview in the central database of the status of the packages.
In the example below, POS10 has not called for the package but POS15 has:
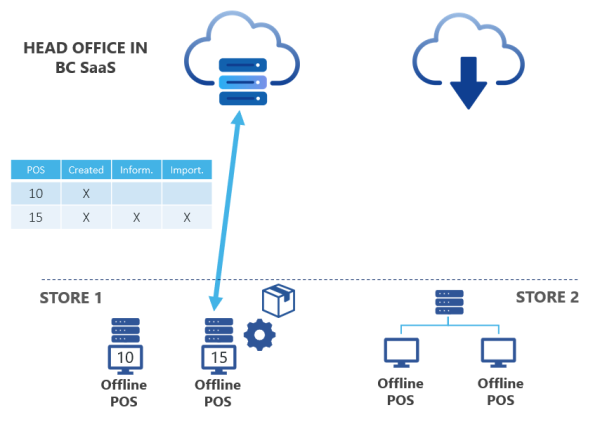
This new method of replication simplifies running the offline POS. There is no middle server or Hybrid server that you have to run on-premises.
More details on the Azure Storage replication
Click the link to see an overview of the Azure Storage replication in the LS Central Help.